Architecture
The architecture that powers Dynamic Sampling is composed of several components that work together to get the organization's sample rate closer to the target fidelity.
The two main components of the architecture are Sentry and Relay, but there are several other sub-components that are used to achieve the desired result, such as Redis, Celery, PostgreSQL, and Snuba.
Relay is the first component involved in the Dynamic Sampling pipeline. It is responsible for receiving events from SDKs, sampling them, and forwarding them to the Sentry backend. In reality, Relay does much more than that. If you want to learn more about it, you can look at Relay docs here.
In order for Relay to perform sampling, it needs to be able to compute the sample rate for each incoming event. The configuration of sampling can be done via a rule-based system that enables the definition of complex sampling behaviors by combining simple rules. These rules are embedded into the project configuration, which is computed and cached in Sentry. This configuration contains a series of fields that Relay uses to perform many of its tasks, including sampling.
Sentry supports two fundamentally different types of sampling, that are described in more detail here.
Inside the project configuration there is a field dedicated to sampling, named dynamicSampling. This field contains a list of sampling rules that are used to calculate the sample rate for each incoming event. The rules will be defined in the rulesV2 field, inside the dynamicSampling object.
A rule is the core component of the sampling configuration and is defined as SamplingRule in Relay.
An example of rule encoded in JSON is the following:
{
"id": 1000,
"type": "trace",
"samplingValue": {
"type": "sampleRate",
"value": 0.5
},
"condition": {
"inner": [],
"op": "and"
},
"timeRange": {
"start": "2022-10-21 18:50:25+00:00",
"end": "2022-10-21 19:50:25+00:00"
},
"decayingFn": {
"type": "linear",
"decayedValue": 0.2
}
}
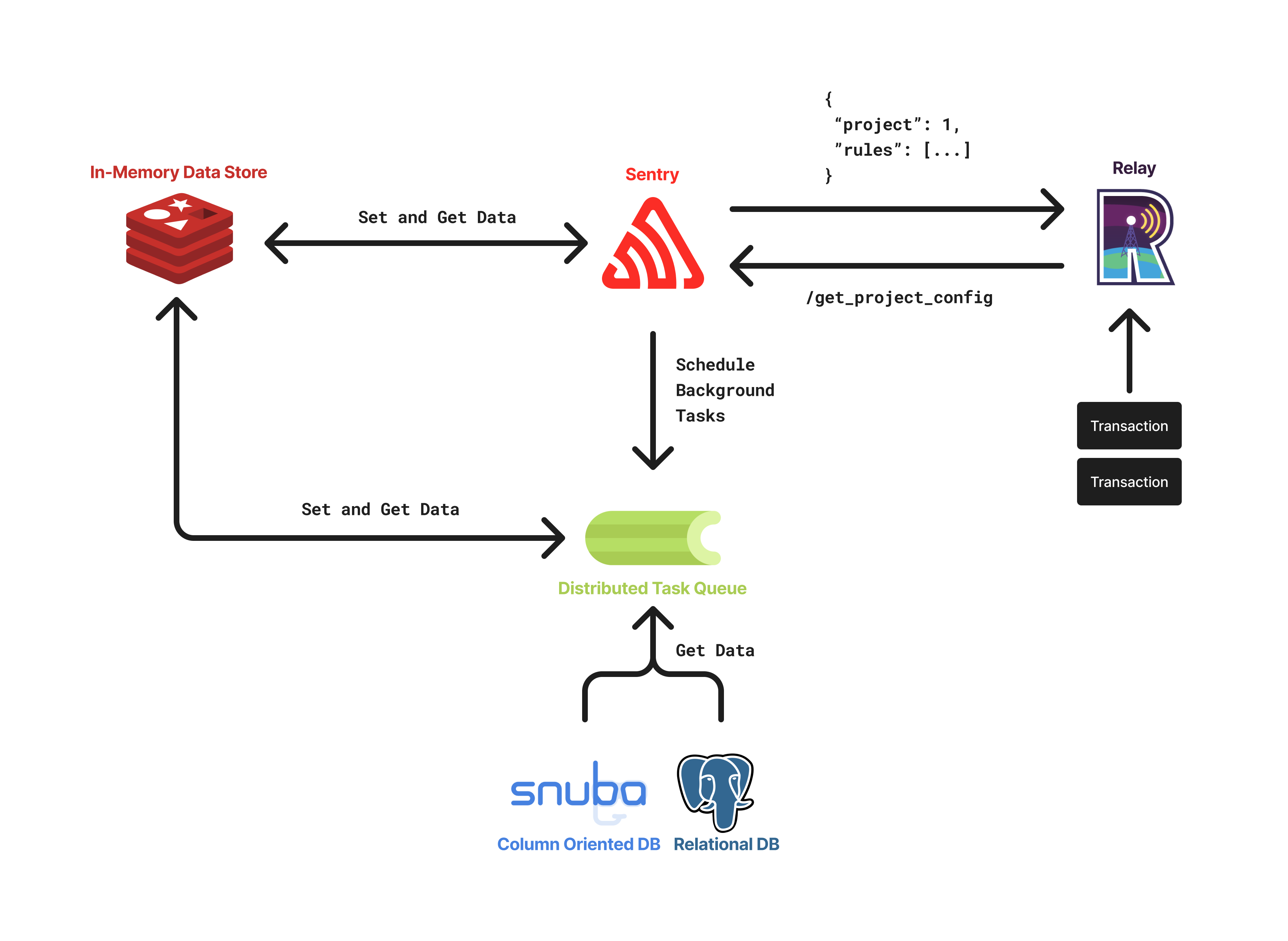
The sampling configuration is fetched by Relay from Sentry in a pull fashion. This is done by sending a request to the /api/0/relays/projectconfigs/ endpoint periodically (defined here).
On the Sentry side, the configuration will be computed in case of a cache miss and then cached in Redis. The cache is invalidated every time the configuration changes, but more details on that will be provided later.
A sampling decision involves:
- Matching the incoming event and/or DSC against the configuration.
- Deriving a sample rate from the mix of
factorandsampleRaterules. - Making the sampling decision with a random number generator.
In case no match is found, or there are problems during matching, Relay will accept the event under the assumption that we prefer to oversample rather than drop events.
Relay samples with two SamplingConfig instances, namely non-root sampling configuration and root sampling configuration. The non-root config is the config of the project to which the incoming event belongs, whereas the root config is the config of the project to which the head transaction of the trace belongs. In case no root sampling configuration is available, only transaction sampling will be performed.
Once both configurations are fetched, Relay will compute a merged configuration (following the algorithm defined here) consisting of all the transaction rules of the non-root project, concatenated to all the trace rules of the root project. This will result in a single configuration containing all the rules that Relay is going to try and match (from top to bottom). The order of the rules of the same type is important, as it will influence the sampling decision.
With the merged configurations, Relay is ready to match the rules. During matching, Relay will inspect two payloads:
- Event: inspected when the non-root project to has at least one transaction sampling rule.
- Dynamic Sampling Context (DSC): inspected when the root project (the project of the head of the trace) has at least one trace sampling rule.
The matching that Relay will perform is going to be based on the samplingValue of the rules encountered. As specified in the section above, based on the type of samplingValue, we will either immediately return or continue matching other rules. More details about the matching algorithm can be found in the implementation here.
Suppose Relay receives an incoming transaction with the following data:
{
"dsc": {
# This is the transaction of the head of the trace.
"transaction": "/hello"
},
# This is the transaction of the incoming event.
"transaction": "/world",
"environment": "prod",
"release": "1.0.0"
}
And suppose this is the merged configuration from the non-root and root project:
{
"rules": [
{
"id": 1,
"type": "transaction",
"samplingValue": {
"type": "factor",
"value": 2.0
},
"condition": {
# Not the actual syntax, just a simplified example.
"trace.transaction": "/world"
}
},
{
"id": 2,
"type": "trace",
"samplingValue": {
"type": "sampleRate",
"value": 0.5
},
"condition": {
# Not the actual syntax, just a simplified example.
"trace.transaction": "/hello"
}
}
]
}
In this case, the matching will happen from top to bottom and the following will occur:
- Rule
1is matched against the event payload, since it is of typetransaction. ThesamplingValueis afactor, thus the accumulated factors will now be2.0 * 1.0, where1.0is the identity for the multiplication. - Because rule
1was a factor rule, the matching continues and rule2will be matched against the DSC, since it is of typetrace. ThesamplingValueis asampleRate, thus the matching will stop and the sample rate will be computed as2.0 * 0.5 = 1.0, where2.0is the factor accumulated from the previous rule and0.5is the sample rate of the current rule.
✨ Note
It is important to note that a sampleRate rule must match in order for a sampling decision to be made; in case this condition is not met, the event will be kept. In practice, each project will have a uniform trace rule which will always match and contain the base sample rate of the organization.
Sentry is the second component involved in the Dynamic Sampling pipeline. It is responsible for generating the rules used by Relay to perform sampling.
Generating rules is the most complicated step of the pipeline, since rules and their sampling values directly impact how far off the system is from the target fidelity rate.
The generation of rules is performed as part of the project configuration recomputation, which happens:
- Whenever Relay requests the configuration and it is not cached in Redis;
- Whenever the configuration is manually invalidated.
The invalidation of the configuration can happen under several circumstances, by calling the following function. Some examples of cases when the recomputation happens are when a new release is detected, when some project settings change, or when the Celery tasks for computing the variable sample rates are finished executing.
The generation of the rules that will be part of the project configuration recalculation is defined here and works by performing the following steps:
- Fetching the list of active biases, since some of them can be enabled or disabled by the user in the Sentry UI;
- Determining the base sample rate specific for each project.
- Computing the rules for each bias by using all the information available at the time (e.g., in memory, fetched from Redis);
- Packing the rules into the
dynamicSampling.rulesV2field of the project configuration; - Returning all the set of rules that will be stored in the project configuration.
Certain biases require data that must be computed from other parts of the system (e.g., when a new release is created) or by background tasks that are run asynchronously.
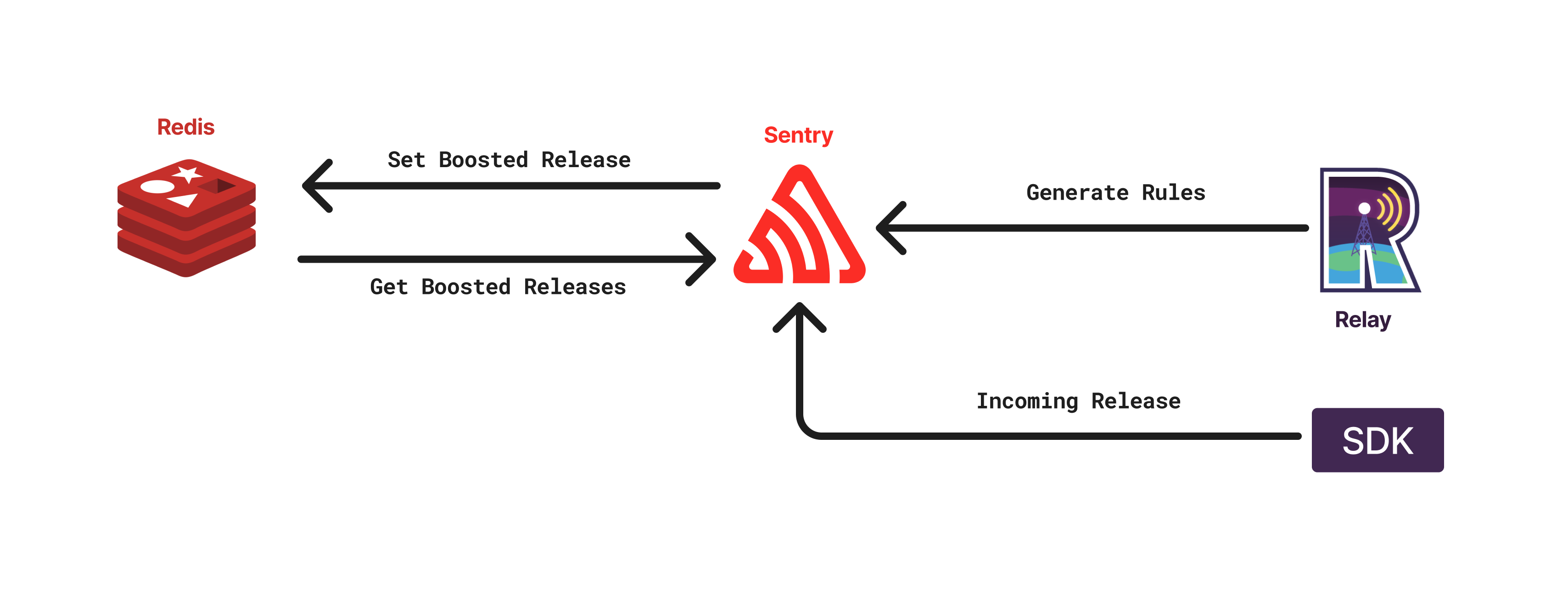
For such use cases, we decided to use a separate Redis instance, which is used to store many kinds of information, such as sample rates and boosted releases. During rule generation, we connect to this Redis instance and fetch the necessary data to compute the rules.
An illustration on how Redis is used for tracking boosted releases (which are used by the boost new releases bias):
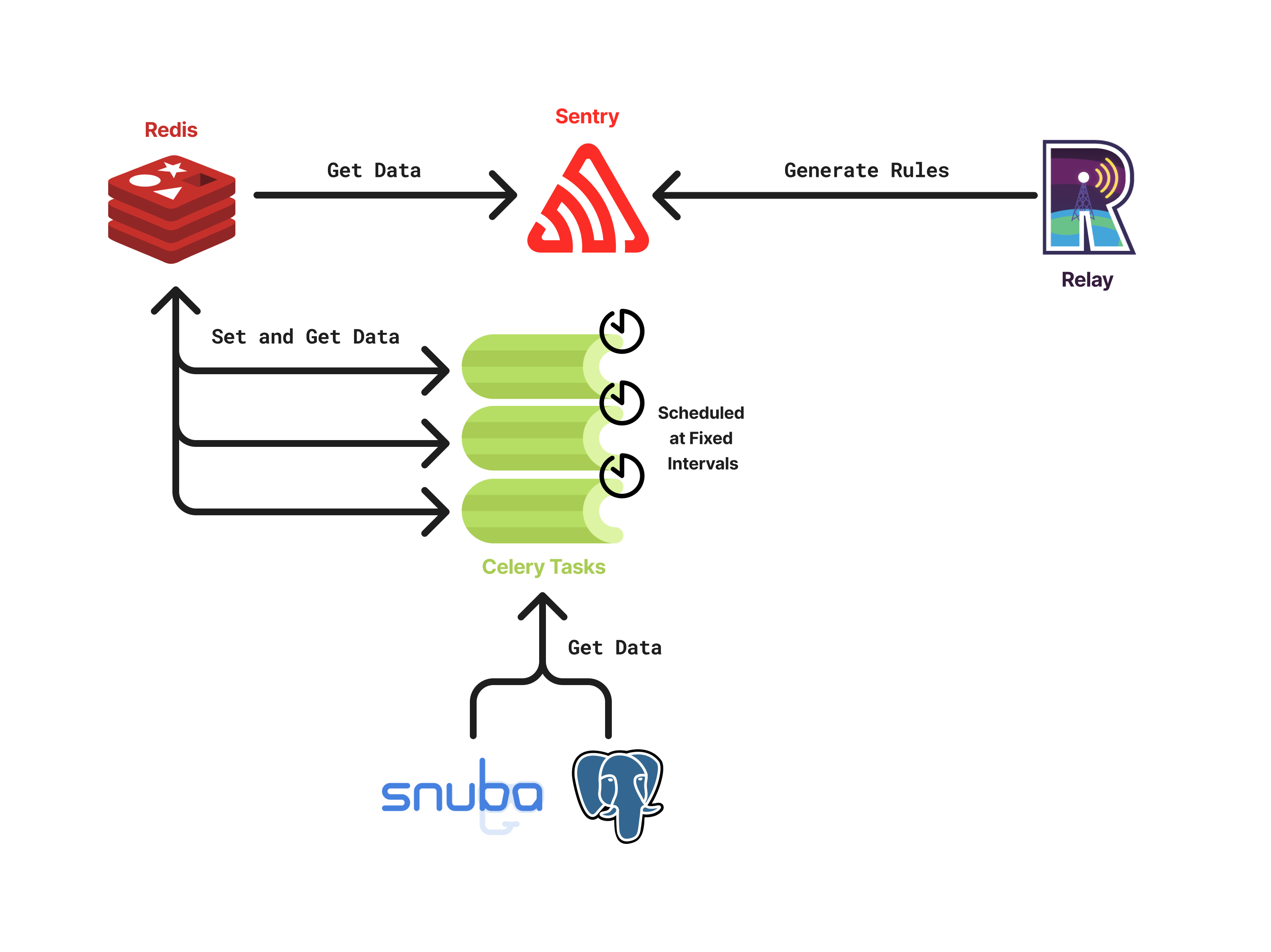
Certain biases require data that must be computed asynchronously by background tasks due to the complexity of the computation (e.g., running cross-org queries on Snuba). This is the case for the boost low-volume projects bias and boost low-volume transactions bias, which need expensive queries to obtain all the necessary data to run the rebalancing algorithms. These tasks are handled by Celery workers, that are scheduled automatically by cron jobs configured in Sentry.
The data computed by these tasks could theoretically be computed sequentially during rules generation but for scalability reasons we opted to use Celery tasks instead. This way, the computation of the data can be parallelized and the rules generation can be performed faster.
An illustration on how multiple Celery tasks are scheduled for computing data required for rule generation:
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").